جستجو در تک بوک با گوگل!

بازدید
تعریف ترمیم
پایگاه¬داده¬ها بالقوه در معرض آسیب است. انواع نقص (عیب) و در نتیجه خرابی ممکن است در پایگاه¬داده¬ها بروز کند. سیستم مدیریت پایگاه¬داده¬ها باید بتواند, در صورت بروز خرابی, پایگاه¬داده¬ها را ترمیم و آسیبها و خسارات وارده بر آن را جبران کند. به عبارت دیگر می¬توان بروز خرابی در سیستم را ناشی از بروز اشتباه در سیستم دانست که خود اشتباه ناشی از ایجاد نقص در سیستم است.[۲]
به عبارت ساده ترمیم یعنی بازگرداندن پایگاه¬داده¬ها به وضع سازگاری که درست قبل از بروز خرابی داشت. به بیان دیگر به آخرین وضع سازگار, به گونه¬ای که اثری از خرابی در آن نباشد.
سلسه مراتب خطا
خطاها انواع مختلفی داشته و در منابع مختلف دسته¬بندی¬های متفاوتی برای آنها معرفی شده است.
از جمله می¬توان خرابی¬ها را به دو دسته عمده خرابی سیستمی و خرابی رسانه¬ای تقسیم کرد. خرابی سیستمی سبب می¬شود تا حداقل یک و معمولاً تمام تراکنش¬های در حال اجرا در سیستم آسیب ببینند ولی داده¬های ذخیره شده در حافظه جانبی دچار خرابی نمی¬شوند. مثل خرابی ناشی از قطع جریان برق. برعکس خرابی¬های رسانه¬ای سبب ایجاد خرابی در تمام یا قسمتی از داده¬های ذخیره شده در حافظه مانا می¬شود و حداقل روی آن دسته از تراکنش¬هایی که در حال استفاده از داده¬ها هستند تأثیر می¬گذارد.
بر اساس شدت سختی خطا از کم به زیاد خطاها به چند دسته تقسیم می شوند : زودگذر، Crash، رسانه¬ای، محلی، اپراتور و خطا های بدخواه.[۲]
خطاهای گذرا آنهایی هستند که موجب از دست رفتن پیغام ها در سیستم های مبتنی بر شبکه می¬شوند . پروتکل¬ها در لایه داده، لایه شبکه و لایه کاربرد می¬تواننند برای رفع و کنترل این گونه خطاها طراحی شوند.
در هنگام رخ دادن یک خطا ی Crash تمام محتویات حافظه و نیز حالات برنامه موجود در پردازنده از بین می¬روند. مکانیسم های استاندارد ترمیم Crash مانند عمل نقطه¬وارسی روی یک حافظه پایدار می¬توانند برای مدیریت این مساله اتخاذ شوند.
خطاهای رسانه¬ای به نقص داده در روش¬های حافظه ماندگار مربوط می شوند. برای مقابله با خطاهای رسانه¬ای نسخه های پشتبان داده وابسته به موقعیت و فرصت باید تهیه شود. این رویه-های تولید پشتیبان ممکن است دستی یا خودکار باشند. ممکن است روی نوارها، دیسک ها و یا کارتریج¬ها ذخیره شوند. واحد پشتیبان¬گیری ممکن است یک نسخه¬برداری کامل پایگاه داده یا یک رکورد ثبت ساده باشد. پس از رخ دادن یک خطای رسانه¬ای نسخه¬های پشتیبان باید برای ترمیم داده¬های از دست¬رفته بازیابی شوند.
خطاهای سایت یا محلی تمام پردازنده های موجود در یک محل را تحت تاثیر قرار می-دهند. این نوع خطاها ممکن است یک مجموعه از ایستگاه¬های کاری در یک اتاق یا یک مجموعه در یک ساختمان را تحت تاثیر قرار دهند.[۲] از آنجایی که این خطاها ماشین¬هایی در محدوده بزرگی را تحت تاثیر قرار می¬دهند این خطا ها می¬توانند اولین نوع خطاهایی باشند که به حادثه یا فاجعه مشهور می¬باشند. طرح¬ها و تسهیلات موجود ترمیم فاجعه می¬توانند برای تحمل خطاهای سایت طراحی شوند. داده¬ها در حافظه¬های پایدار و کارتریج¬های پشتیبان ممکن است جبران ناپذیر باشند. جداسازی جغرافیایی سخت افزارهای اضافی و داده¬ها می تواند به ترمیم این گونه از حوادث کمک کند.
اعمال بشر باعث لایه بعدی از حوادث می شوند. به عنوان مثال ممکن است شخصی به صورت تصادفی نسخه¬های جاری و پشتیبان را با هم اشتباه کرده و آخرین نتیجه نوشته شده را دوباره بنویسد. بر عکس خطاهای محلی، مشخص کردن محدوده خطاهای اپراتور و تشخیص داده-های خوب از داده¬های بد کار ساده ای نمی¬باشد. رویه های ترمیم معمولاً وقت¬گیر هستند. خطاهای اپراتور را می¬توان بوسیله محدودسازی اختیارات کاربرهای کم تجربه و تهیه حافظه¬های پشتیبان کافی به حداقل رساند.[۱]
بدترین نوع خطا، خطاهای بدخواه یا رومی است که می¬توانند تمام قطعات اطلاعات را نابود سازند. یک نمونه از آنها ویروس کامپیوتری مثل Michelangelo است که قادر است پردازنده¬های اولیه و پشتیبان ونیز نوارهای پشتیبان را آلوده سازد. این نمونه از خطاها می¬توانند بوسیله وادارسازی پروتکل¬ها به توسعه خود بوسیله کنترل¬های ایمنی بسیار سخت و تهیه تعداد نسخه¬های پشتیبان کافی کاهش داد.[۱]
معماری سیستم و طبقه بندی ترمیم¬ها
معماری اصلی سیستمی که ما در نظر می¬گیریم شامل یک سایت اولیه و یک سایت پشتیبان است (شکل ۱). سایت اولیه ممکن است یک سیستم پایگاه¬داده درست یا یک واحد دیسک تنها را ارایه کند. در موارد گذشته، یک واحد پردازش یک کامپیوتر همه منظوره همراه با چندین دیسک و نوار است و در موارد اخیر، یک واحد پرداش یک کنترل کننده دیسک است که هیچگونه نواری در سایت ندارد. به موازات سایت اولیه، سایت پشتیبان نیز شامل واحد پردازش، دیسک و نوار است که اطلاعات کافی در آن ذخیره می¬شود تا در صورتی که سایت اولیه از کار افتاد اطلاعات موجود در پشتیبان برای ترمیم داده¬های از دست رفته در سایت اولیه مورد استفاده قرار گیرد. بنابراین پشتیبان فقط هنگام خطا مورد استفاده قرار می گیرد.[۱]
شکل ۱
بسته به اینکه سایت پشتیبان چگونه عمل می کند ما سیستم های قابل ترمیم را به دو دسته ترمیم داده و ترمیم سرویس تقسیم می¬کنیم. یک سیستم ترمیم داده هنگامی که یکی از اجزا سیستم از کار افتاد، فقط داده ها را ترمیم یا به حالتی سازگار باز می¬گرداند. سیستم ممکن است سرویس دهی خود را تا زمان تعمیر اجزا متوقف کند. در سیستم ترمیم سرویس, داده¬ها در حین ارایه سرویس¬ها پیوسته ترمیم می¬شوند. تقسیم بندی بالا در شکل ۲ به صورت روشن¬تری نمایش داده شده است.[۱]
ترمیم داده به همزمان سازی داده، تکرار داده و خوشه¬بندی واحدهای عمل تقسیم می-شود. همزمان سازی داده که برقراری سازگاری بین داده و پشتیبان را شامل می¬شود به دو صورت بدون تاخیر و با تاخیر صورت می¬گیرد. همزمان¬سازی بدون تاخیر هنگامی که سیستم اولیه در حال ارائه سرویس است صورت می¬گیرد در حالی که همزمان سازی با تاخیر هنگامی که سیستم های اولیه داده¬ها را تغییر نمی¬دهند صورت می¬پذیرد. به عنوان مثال یک پایگاه¬داده بانکداری پشتیبان سازی داده¬ها را در شب هنگامی که تراکنش¬ها در حال پردازش نیستند انجام می دهد. به صورت مشهور، نسخه¬های پشتیبان سیستم¬های دسته¬ای به وسیله یک متد با تاخیر که سایت-های داغ نامیده می¬شوند صورت می¬پذیرد.[۲] یک سایت پشتیبان عادی پایگاه¬داده را بر اساس آخرین کپی پایگاه داده بایگانی شده و با استفاده از تغییرات فایل ثبت که تا آن زمان به پایگاه داده اعمال شده اند دوباره سازی می نماید.
پشتیبان بدون تاخیر از کپی¬های پایگاه¬داده به روز شده¬تر در تهیه نسخه پشتیبان استفاده می¬کند. تغییرات در سایت اولیه برای انجام اعمال فوری در پایگاه¬داده پشتیبان به سایت پشتیبان تحویل داده می¬شود. برای حذف هرگونه تفاوت در سایت¬های اولیه وپشتیبان، هر دو سایت واحدهای عملیاتی خود را در روشLok-step انجام می¬دهند بدین معنی که هر عملیاتی در سایت اولیه باید با عملیات متناظر خود در سایت پشتیبان همزمان شود. این روش هزینه ارتباط بالایی می¬طلبد و نیز پرداش واحدهای عملیاتی در سایت اولیه پایین می¬آورد. به عنوان یک مصالحه، سایت¬های اولیه و پشتیبان به صورت سستی با هم هم¬زمان می¬شوند. سایت اولیه واحدهای عملیاتی را که باید اجرا شود به سایت پشتیبان می¬فرستد ولی منتظر اجرای آنها بوسیله سایت پشتبان نمی¬ماند. این عمل باعث ایجاد اختلاف اندکی بین پایگاه داده اولیه و پشتیبان می¬شود که بسته به تاخیر ارتباط و سرعت پردازش سایت¬ها متفاوت است.[۳]
شکل ۲ – تقسیم بندی سیستم های ترمیم پذیر
تکرار داده به دو صورت انفعالی و فعال تقسیم بندی می¬شوند. در تکرار داده انفعالی، اقلام داده ای تکرار شده به ثانویه ها ارسال شده و بدون پرداش در وسایل حافظه سخت افزاری ذخیره می شوند. در تکرار داده فعال ، اقلام داده تکرار شده به ثانویه ها ارسال شده و سپس برخی پروتکل های تکرار در ثانویه ها اجرا می شوند
ریزدانه¬گی واحدهای عملیات نیز باید در سیستم های ترمیم پایگاه داده در نظر گرفته شوند. برخی سیستم¬ها واحدهای کوچکی از عملیات مانند خواندن و تغییر اجزای داده را پشتیبانی می¬کنند. عملیات به صورت ضمنی اتمیک هستند. [۲]این ایده برای سسیستم های پردازش تراکنش که در آنها عملیات ها به صورت یک تراکنش گروه بندی می شوند استفاده می شود. اتمیک بودن اجرای تراکنش تضمین می شود: تمام عملیات یا باید به طور کامل اجرا شوند یا اصلا نباید اجرا شوند.
در سیستم¬های ترمیم سرویس، پشتیبان, داده¬ها را پس از رخ دادن نقص در سایت اولیه ترمیم کرده و سپس یک سایت اولیه جدید می¬گیرند. پس از اینکه سایت اولیه اصلی ترمیم شد، سایت ترمیم شده یا به عنوان سایت اولیه به فعالیت خود ادامه می¬دهد یا خود را به عنوان سایت پشتیبان معرفی می¬کند. یک سیستم ترمیم داده در صورتی که اجزای سخت افزاری تکرار شده کافی در سایت پشتیبان با مد خرابی غیر وابسته داشته باشد می تواند به یک سیستم ترمیم سرویس ارتقا یابد.
اگر سایت پشتیبان یک سیستم ترمیم سرویس قبل از گرفتن سایت اولیه جدید منتظر ترمیم داده باشد ، کاربر مدت زیادی معطل خواهد شد. بنابراین بعضی از سیستم ها برای پذیرفتن سرویس جدید درخواست شده از سوی کاربر در حالی که داده¬ها در حال ترمیم هستند طراحی می¬شوند. به سیستم با این ویژگی سیستم بدون وقفه می گویند.یک نمونه سیستم های بدون وقفه جفتی هستند.[۲]
روش تکرار داده انفعالی برای مقاومت در برابر خطاهای گذرا، خطا های رسانه¬ای وCrash کردن پردازنده طراحی شده است. روش های عادی تکرار انفعالی شامل روش دیسک منعکس شده، RAID، دیسک منعکس شده دور و روش سایت اولیه است.
روش دیسک منعکس شده فقط یک خطای رخ داده در دیسک ها را تحمل می کند که این کار را با داشتن دو دیسک یکسان که به صورت همزمان در سرتاسر یک کنترلر دیسک عادی تغییر می یابند انجام می دهد. هر کدام از دیسک¬های در حال کار برای سرویس دهی به درخواست داده کافی می باشند. این سیستم دیسک بسیار گران بوده و در مقابل رخ دادن یک فاجعه (disaster) غیر قابل ترمیم است.[۱]
روش RAID یک گروه از G دیسک داده به اضافه یک دیسک توازن که به کنترلر دیسک عادی متصل است می باشد. بلاک توازن ، exclusive-or G بلاک داده¬ی متناظرش را ذخیره می¬کند. خواندن یک بلاک داده از RAID به خواندن بلاک از یک دیسک داده مناسب برگردانده می¬شود. نوشتن یک بلاک داده به دیسک شامل نوشتن بلاک داده به دیسک به علاوه تغییر بلاک توازن متناظر آن است. روش RAID می تواند عمل خود را با وجود رخ دادن یک خرابی دیسک ادامه دهد. عمومی ترین روش RAID سطح ۵ نامیده می¬شود. در این روش بلاک¬های داده و بلاک¬های توازن بین دیسک¬هایی که بار کار را به صورت مساوی پخش کرده و تنگراه¬ها به دیسک توازن را برداشته¬اند تقسیم می¬شوند. هم دیسک منعکس شده و هم RAID در مقابل فجایع (disaster) قابل ترمیم نیستند.
روش دیسک منعکس شده دور یک بسط از روش دیسک منعکس شده است. تغییرات به دیسک منعکس شده¬ای که در سایتی دور در طول یک شبکه قرار دارند به صورت غیر همزمان اعمال می¬شوند. این روش در مقابل حادثه¬ای که در سایت اولیه رخ می دهد قابل ترمیم است هر چند که داده¬های منتشر نشده به سایت دور از بین می¬روند. روش دیسک منعکس شده دور می-تواند با استفاده از بیش از یک نسخه پشتیبان به روش سایت اولیه تعمیم پیدا کند. تغییرات در سایت اولیه انجام شده و سپس به سایت ثانویه به صورت غیر همزمان منتشر می¬شوند. برای ترمیم خطای رخ داده شده در سایت اولیه، یکی از سایت¬های ثانویه به عنوان اولیه جدید انتخاب می¬شود.
در روش تکرار داده فعال ، سایت¬های پشتیبان به اندازه کافی قدرت پردازشی و منابع مورد نیاز برای تسهیم بار کاری سایت اولیه را دارا هستند. در روش توافق اکثریت ، یک عمل تنها وقتی که اکثریت سایت ها با انجام آن موافق باشند قابل انجام است. بازده این روش بالاتر است ولی هزینه عمل خواندن و نیز نوشتن متوسط است. توافق اکثریت می تواند به روش توافق حد نصاب تعمیم پیدا کند . به جای گرفتن رضایت اکثریت سایت ها برای یک عمل خاص ، فقط رضایت یکسری سایت مرتبط که به نام حد نصاب یا quorum هستند نیاز است . پروتکل های توافق حد نصاب در سایز quorum ها ،overhead و تحمل پذیری خطا متفاوت هستند.
روش RAID توزیع شده تعمیمی از روش RAID انفعالی به یک روش فعال است.سیستم شامل G+2 سایت است . G/G+2 از کل بلاک ها برای داده ها مورد استفاده قرار می گیرد ، ۱/G+2 از کل بلاک ها برای ذخیره سازی parity و ۱/G+2 از کل بلاک ها برای ذخیره سازی به عنوان یدکی استفاده می شوند. این بلاک ها در سر تا سر G+2 سایت توزیع شده اند. در هر مورد یک خطای رخ داده در دیسک یا هر مورد از یک خرابی رخ داده در یک سایت ، نوسازی داده های از بین رفته با استفاده از دیسک های در دسترس امکان پذیر است . اطلاعات ساخته شده همچنین می توانند در بلاک های یدکی در دیسک های موجود ذخیره شوند.[۱]
مانند پروتکل توافق حد نصاب ، روش RAID توزیع شده هزینه همزمانی زیای بین تمام سایت هایی که بخش هایی از داده تکرار شده را شامل می شوند را باید متحمل شود. برتری روش RAID توزیع شده به پروتکل توافق حد نصاب کم بودن میزان افزونگی داده است ولی قبل از آن معایبی دارد که از آن جمله الگوریتم های پیچیده تر قرار دادن داده و ترمیم پذیری کمتر سایت ها در برابر خرابی هاست.
خوشه بندی واحد های عملیات می تواند به دو صورت بر اساس عملیات و بر اساس تراکنش تقسیم شود.یک سیستم بر اساس عملیات ، عملیات های اتمیک پایه مانند خواندن و نوشتن و نیز عملیات های سطح بالاتر مانند افزایش و en queue را پشتیبانی می کند. بسیاری از این سیستم ها مانند سیستم دیسک منعکس شده ، Lok-step هستند و واحد های حافظه در سایت های اولیه و پشتیبان با لینک های سرعت بالا که معمولا با سنجش زمان ، همزمان هستند به یکدیگر متصل هستند.هر تغییری در واحد حافظه اولیه بلافاصله به واحد حافظ پشتیبان اعمال می شود.در سیستم های دیگر، لینک ها بین سایت ها سست تر و غیر همزمان هستند.یک مورد از این سیستم ها ، سیستم فایل توزیع یافته است که تغییرات رخ داده در سرور اولیه کلا به صورت غیرهمزمان به سرور پشتیبان منتقل می شوند.
سیستم های بر اساس تراکنش ، تراکنش هایی را پشتیبانی می کنند که اجرای برنامه هایی را که به اشیاء پایگاه داده دسترسی می یابند ، شامل می شوند. پی در پی پذیری پذیرفته شده ترین معیار صحت در پردازش تراکنش هاست. یک جدول همزمانی تراکنش های همروند زمانی پی در پی پذیر است که معادل با یک جدول هزمانی سریال اجرای آن تراکنش ها باشد .[۳]هنگامی که یک تراکنش در سایت اولیه اجرا می شود ، عملیات های تغییر به سایت پشتیبان منتشر می شوند. کمترین انشعاب به بهترین تلاش صرف شده در نگهداری پشتیبانی که شامل بیشترین تغییرات قانونی ممکن است اشاره دارد. این عمل معمولا با حداقل کردن تفاوت بین تراکنش های سایت های اولیه و پشتیبان حاصل می شود.
سیستم های ۱- ایمن و ۲- ایمن سطوح مختلفی از انشعاب را پشتیبانی می کنند. یک سیستم پردازش تراکنش زمانی ۲- ایمن است که تمام تراکنش ها موجود در سیستم اتمیک باشند : چه تراکنش هایی که تغییرات شان به سایت های اولیه و پشتیبان منعکس می شود و چه تراکنش هایی که در هیچ یک از این سایت ها اجرا نمی شوند. با در نظر گرفتن سایت پشتیبان به عنوان بخشی از تراکنش های تویع شده ، پروتکل تثبیت دو فازی ممکن است برای پیاده سازی سیستم ۲- ایمن مورد استفاده قرار گیرد. ولی حداقل یک تاخیر round-trip اولیه – پشتیبان در تثبیت شدن تراکنش ها اجتناب نا پذیر است. این تاخیر طولانی تراکنش ها را وادار می سازد که قفل خود را به مدت طولانی تری نگهداری کنند و در نتیجه درگیری افزایش و توان عملیاتی کاهش می یابد.
برای اجتناب از این مساله ، اکثر سیستم ها یک روش ۱- ایمن را اتخاذ می کنند که در آن به تراکنش ها اجازه داده می شود قبل از اینکه تغییرات به پشتیبان منتشر شوند تثبیت شده و قفل خود را آزاد کنند. بنابراین تاخیر ارتباطی در تثبیت شدن وجود ندارد ولی اگر خطا قبل از انتشار یک تراکنش به پشتیبان رخ دهد ممکن است تراکنش تثبیت شده در سایت اولیه از بین رود. با این وجود ، روش بالا به عنوان یک روش به اندازه کافی خوب برای سیستم های عملی در نظر گرفته می شود.[۳] برای بدست آوردن حداقل انشعاب در این روش نیاز است که تراکنش های از بین رفته در طول رخ دادن یک خطا در سایت اولیه به صورت مینیمم نگهداری شود.
تقریبا تمام محصولات بازرگانی از یک روش ۱- ایمنی به منظور کارایی استفاده می کنند ولی در عین حال روش ۲- ایمنی را برای تراکنش های بحرانی و با ارزش پشتیبانی می کنند.
طراحی ترمیم فجایع (disaster recovery)
ترمیم فاجعه شامل جنبه¬های انسانی به همراه جنبه¬های سیستم است. ما جنبه¬های سیستم مانند صحت نیازمندی¬هایی که بوسیله سیستم پس از اجرای رویه¬های ترمیم فاجعه تضمین می¬شود و انواع مقدماتی که باید برای سیستم جهت نگهداری اطلاعات مورد نیاز برای ترمیم فراهم شود را مورد بررسی قرار می¬دهیم.
به علاوه ترمیم یک حادثه چه در سطح عملیات (به صورت خودکار) و چه در سطح مدیریت (به صورت غیر خودکار) باید تحت نظارت انسان انجام شده و یک زنجیره از دستورات ایجاد شود. تیم ترمیم فاجعه باید جهت تولید طرح ترمیم شکل بگیرد. تیم باید ابتدا مرکز پردازش داده شامل پیکربندی سخت¬افزار و نرم¬افزار و محیط سیستم، ورودی و خروجی داده، تقسیم¬بندی کارها به کارهای بحرانی و غیر بحرانی ، رویه پشتیبان پایگاه داده و طرح های ترمیم فاجعه موجود را مورد بررسی قرار می دهد.پیکربندی برای سیستم بهبود پذیر در برابر حادثه معرفی شده و پشتیبان پایگاه داده و رویه های حافظه off-site به وجود می¬آیند. طراحی سایت پشتیبان و توانایی های آن بازبینی و پیاده سازی شده و در پایان طرح ترمیم تست می شود. جزئیات طرح ترمیم بستگی به حمایت های سیستم دارد.[۲]
اغلب سیستم های پایگاه داده تجاری عمومی مانند Sybase , Oracle , DB2 پشتیبانی¬های کاملی از ترمیم فاجعه فراهم نمی آورند. Sysbase گزینه هایی برای تحمل خطا و بهبود توانایی سیستم فراهم می آورد از جمله پشتیبانی های چند پردازنده مناسب ، سرورهای همنشین ، ابزار منعکس شده ، سرورهای هدایت کننده . به علاوه برای پشتیبانی ترمیم crash به پایگاه داده اجازه می دهد که پشتیبان تهیه کند و Checkpoint ایجاد کند. هم سرور های هم نشین و هم ابزار های منعکس شده در فرایند ترمیم شرکت می کنند. یک سرور همنشین با روشی مشابه روش سرور اولیه / پشتیبان در مقابل خطای پردازنده مقاومت می کند. هنگامی که سایت اولیه خراب می شود تراکنش های تثبیت نشده قبل از اینکه توسط همنشین گرفته شوند بازگردانده می شوند.
شیوه منعکس شده یک بسط از دیسک است که برای مقابله با خطا های سخت افزاری بوجود آمده اند. داده ها تکرار شده و در اولیه و انعکاس آن به صورت شفافی ذخیره می شوند. برای حمایت از ترمیم فاجعه ، ناظر سیستم باید طرح ترمیم فاجعه را تهیه و رویه های پشتیبان پایگاه داده ، حافظه و بازیابی را راه اندازی کند .
در Oracle پشتبان گیری پایگاه داده هم بوسیله پایگاه داده بسته ( پشتیبان سرد ) وهم بوسیله پایگاه داده در دسترس ( پشتیبان گرم ) انجام می گیرد. ترمیم خطا های crash می-تواند به صورت خودکار باشد. تراکنش های تثبیت نشده پس بازگرداندن اطلاعات فایل های کنترل ضروری بازگردانده می شوند . دیسک منعکس شده برای مقابله در برابر خطاهای مدیا اتخاذ می شود . تنها ضروری است که فایل¬های ثبت انجام دوباره موجود و نیز فایل های ثبت انجام دوباره بایگانی شده در شکلی از حافظه پایدار ، برای ترمیم خطای مدیا ، منعکس شوند. کارایی Oracle می تواند بوسیله تکرار داده دور در یک سرور محلی بهبود یابد. کپی های کش شده می توانند از طریق مکانیسم ماشه Oracle به محض اینکه نسخه اصلی دور تغییر کرد ، تغییر یابند .
محیط DB2 برای ترمیم خودکار حادثه طراحی نشده است مگر اینکه سیستم پشتیبان و کنترل کننده¬های حافظه نصب شده و برای ارایه خدمات پیکر بندی شوند. با این وجود ابزارهای استاندارد می توانند اجزاء داده شامل پشتیبان کپی تصویر ، نوارهای ثبت، جدول¬های داخلی DB2 و مجموعه داده را در ترمیم عادی دستکاری نمایند. تیم ترمیم فاجعه باید طرح ترمیم خودشان را گسترش دهند.[۲]
از آنجایی که اغلب سیستم¬های پایگاه¬داده پشتیبانی ترمیم فاجعه را فراهم نمی¬کنند ، سخت افزارهای خاصی برای مدیریت حافظه باید نصب شوند به طوری که داده¬های مورد نیاز برای ترمیم را در دسترس قرار دهند. به عنوان مثال، مدیر دادهEMC به عنوان یک سیستم پشتیبان کامل یک راه حل برای پشتیبانی شبکه¬ای بدون تاخیر و ترمیم برای Oracle و Sybase می¬باشد.EMC از سیستم ۵۰۰۰ حافظه سیمتریکس که امکان داده دور سیمتریکس ( SRDF ) و نیز امکان پشتیبان / بازیاب سیمتریکس ( SBRF ) را فراهم می¬کند استفاده می¬کند .از طریق SRDF ، داده¬ها در زیر سیستم¬های حافظه دور در زمان واقعی تکرار می¬شوند. SBRF ممکن است برای تهیه یک عملیات سیستم پیوسته از طریق راه گزینی زیر سیستم سریع و کوچ داده¬ها در بین زیر سیسستم¬ها استفاده شود. کنترل کننده ۳۹۹۰ آی بی ام یک کپی دور برای پشتیبان دور بدون تاخیر که به صورت سست همزمان شده است فراهم می¬آورد .[۱] این گزینه کپی دور مبسوط (XRC) پیش فرض ، برای دسترسی داده بالا جهت پشتیبان داده غیر همزمان مفید است .کنترل کننده همچنین کپی دور جفت- به – جفت ( PPRC ) که پشتیبان داده دور Lock-step شده را پشتیبانی می کنند را فراهم می آورد. این موضوع عمل ترمیم را تسهیل می بخشد. یک طرح ترمیم فاجعه به صورت عادی بوسیله بازیابی داده های پشتیبان دور و پردازش تغییرات از دست رفته برای سیستم های پشتیبان غیرهمزمان اجرا می شود.
بسته به سازماندهی داده پشتیبان و رویه های ترمیم ، سه طرح ترمیم عمومی وجود دارد : اولین روش به روش پتک مشهور است ک روش با تاخیر برای کاربردهای غیر بحرانی وغیر فراری است که در طول ۲۴ ساعات شبانه روز اجرا نمی شوند. در این روش نیاز است که اجرای پایگاه داده متوقف شده ، از پایگاه داده موجود روبرداری شده و به صورت off-site مانند پشتیبان سرد ارسال شود. استراتژی دوم ، فضای جدول ها و شاخص مجموعه داده های ” عقب پشت ” یک پایگاه داده مانند DB2 را کپی می کند. به وسیله استرتژی سوم که به نام چاقو شناخته می شود پشتیبان های کپی تصویر بدون تاخیر زمانی روی نوارها ایجاد شده و نوارها برای پشتیبان گیری یک جدول در یک زمان به سایت دور ارسال می شوند.
دو محصول پایگاه داده ، IMS/ESA ی IBM و امکان داده دور Tandem حمایت ترمیم فاجعه کاملی تهیه می کنند . IMS / ESA ترمیم سایت دور ( RSR ) را پشتیبانی می کنند که بسط ترمیم IMS به سایت های دور است . امکان داده دور Tandem هم یک جریان log عادی برای سیستم های پایگاه داده ای است که سرویس های بدون وقفه ارایه می کنند.
هنگامی که یک خطا در سایت اولیه ییدا می شود اپراتور باید تصمیم بگیرد که آیا نسخه پشتیبان باید مورد استفاده قرار گیرد. از آنجا که ممکن است سیستم قادر به تشخیص یک خطای ارتباط با خطای سایت نباشد ، این تصمیم نباید بوسیله پشتیبان به صورت خودکار اتخاذ شود. مدت زمان خروج سایت اولیه ممکن است کوتاه بوده و به گرفتن پشتیبان نیازی نباشد. پس از اینکه تصمیم گرفتن پشتیبان اتخاذ شد ، پشتیبان بر اساس اطلاعات موجود در log خود ابتدا تاثیرات تراکنش های تثبیت شده را نصب کرده و تاثیر تراکنش های تثبیت نشده را خنثی می کند . سپس خروجی از ترمینال ها به سوی پشتبان که حالا به عنوان اولیه شناخته می شود ، هدایت می شوند. هنگامی که سیستم اولیه تعمیر شد، تلاش می کند بر اساس یک log محلی خود را به حالتی سازگار ترمیم کند.[۳]
اگر خطا به اندازه ای سخت باشد که سیستم اولیه اصل نتواند خود را به حالتی سازگار بازگرداند ، یک روبرداری پایگاه داده از اولیه جاری به روی سیستم اصلی نصب خواهد شد . سپس اولیه اصلی خود را به یک سیستم پشتیبان تبدیل کرده و پروتکل های ترمیم خطا برای سیستم های پشتبان را دنبال می کند . در انتهای رویه ترمیم نقش دو سیستم تعویض می شود یعنی اولیه اصلی تبدیل به پشتیبان و پشتیبان اصلی تبدیل به اولیه می شود. اگر ضروری باشد می تواند پیکربندی اصلی بوسیله یک طرح تعویض بازیابی شود . اگر پشتیبان خاموش شود ، اولیه می تواند به صورت عادی به فعالیت خود ادامه دهد ولی رکوردهای log نمی توانند به سایت پشتیبان ارسال شوند.به محض اینکه پشتیبان تعمیر شد دریافت رکوردهای log را از نقطه ای که آنها را ترک کرده بود از سر می گیرد. اگر مدت خطا طولانی باشد ممکن است زمان زیادی برای همگام شدن پشتیبان با اولیه صرف شود. اگر پشتیبان برای دوره مبسوطی از زمان در دسترس نباشد ، اجازه دادن به پشتیبان برای همگام شدن با اولیه به صورت تدریجی امکان ناپذیر است.[۱] در عوض یک اپراتور می تواند یک روبردای جدید بدون تاخیر از پایگاه داده اولیه تهیه و روی سیستم پشتیبان نصب کند.سپس log های تولید شده پس از روبرداری بدون تاخیر به پشتیبان اعمال می شوند. هنگامی که پشتیبان به اولیه همگام شد تمام سیستم به حالت عادی برمی گردد .
رویه های طرح تعویض به این صورت عمل می کنند : ابتدا اولیه دریافت تراکنش های جدید را متوقف می کند . پس از اینکه تمام تراکنش های موجود تکمیل شدند ، اولیه یک نشان خاص درون log خود نوشته و سپس خودش را به یک پشتیبان تبدیل می کند . پشتیبان اصلی می تواند پس از پردازش تمام رکوردهای log تا قبل از نشان ویژه خود را به اولیه تبدیل کند . سپس سیستم با پذیرفتن ورودی های دوباره هدایت شده توسط سیستم اولیه جدید ، عملیات عادی خود را از سر می گیرد.


آموزش های عمومی برای ورود به بازار کار ۱٫۳۳/۵ (۲۶٫۶۷%) ۳ امتیازs موضوع : آموزش های عمومی برای ورود به بازار کار کسب مهارت برای ورود به بازار کار امروز در تک بوک میخواهیم سایتی رو به شما معرفی کنیم که میتونید توش […]

ترفندهای جدید در پاورپوینت ۳٫۰۰/۵ (۶۰٫۰۰%) ۱ امتیاز PowerPoint ابزاری ساده و پرکاربرد برای ارائه کنفرانس، سخنرانی و تحقیقات است و با امکاناتی که روز به روز به آن افزوده میشود، کار با این ابزار ساده تر از گذشته شده است.
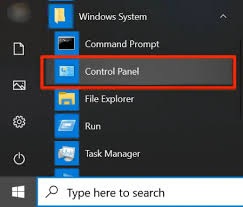
۱۱ روش آوردن کنترل پنل در ویندوز ۱۰ ۳٫۰۰/۵ (۶۰٫۰۰%) ۱ امتیاز تمام قسمت های ویندوز ۱۰ بهینه شده است از ابزارها گرفته تا قسمت هایی که مربوط به تنظیمات این سیستم عامل می باشد.

۱۱ امتیاز برای مهاجرت به ویندوز ۱۰/ با عرضه ویندوز ۱۰ بررسی امکانات و ویژگیهای آن آغاز شده است. اگر چه این ویندوز به علت برخی قابلیت هایش از توانمندی بیشتری برای جمع آوری اطلاعات شخصی کاربران برخوردار است، اما مزایای زیادی هم دارد.

اندازه مناسب و قابل حمل بودن سیستمعاملهای مختلف، حافظه فلش مموری را به دستگاهی بسیار پرکاربرد برای انتقال اطلاعات تبدیل میکند.

همزمان با افزایش بدافزارها، کرمهای اینترنتی و تروجانها، هکرها و سارقان اطلاعات همواره به دنبال راههایی به منظور سرقت اطلاعات و دسترسی به حسابهای بانکی و گاهی بوجود آوردن اختلالات الکترونیکی بوده اند.




دانلود کتاب اندروید طعم مرگ ۳٫۸۲/۵ (۷۶٫۴۷%) ۱۷ امتیازs ♥ عناوین اصلی کتاب اندروید ” طعم مرگ ” شامل: ♥ فصل اول: حقیقت مرگ ♥ فصل دوم: اقسام مرگ ♥ فصل سوم: احتضار و خصوصیات آن ♥ فصل چهارم: سکرات مرگ ♥ فصل پنجم: ترس […]

دانلود کتاب اندروید مهر مهتاب _ کرامات حضرت فاطمه ۴٫۰۰/۵ (۸۰٫۰۰%) ۷ امتیازs سخن مولف : در این کتاب، ابتدا سى کرامت نقل کرده ام سپس در فصل دوم به چند بحث پرداخته ام: «آیا خواب حجّت است؟ چگونه مى شود به خواب اعتماد […]

دانلود کتاب اندروید گوهر هفتم : چهل سخن از امام کاظم ۳٫۷۹/۵ (۷۵٫۷۱%) ۱۴ امتیازs سخن مولف : ما خود را پیرو اهل بیت علیهم السلام مى دانیم و محبّت آنان را در دل داریم، خدا به آنان مقام عصمت داده است و از […]

معرفی چند کتاب خوب و مفید یکی از مشکلاتی که اغلب علاقمندان به کتاب با آن روبرو میشوند، عدم شناخت کتابهایی است که ارزش مطالعه کردن را داشته باشند. این که ما چه کتابی بخوانیم که بتواند به مذاق ما خوش آمده و به […]

نقش شرکت حسابداری و خدمات مالیاتی در چالش های مالیاتی پزشکان// حرفه پزشکی، با وجود جایگاه رفیع و نقشی حیاتی در جامعه، همواره با چالش های متعددی در حوزه مالیات روبرو بوده و هست.

بهترین ترجمه جنین شناسی لانگمن کدام است + مقایسه ۴٫۰۰/۵ (۸۰٫۰۰%) ۸ امتیازs بهترین ترجمه جنین شناسی لانگمن کدام است + مقایسه جنین شناسی یکی از چالش برانگیز ترین دروس علوم پایه است که مطالعه آن خود چالش های خاص خود را دارد. […]
تمامی حقوق و مطالب سایت برای تک بوک محفوظ است و هرگونه کپی برداری بدون ذکر منبع ممنوع می باشد.






به نکات زیر توجه کنید